When Containers Met AI:The New Cloud Playbook for 2026
Kubernetes was built to run stateless web apps. Docker was built to ship software reliably. Neither was designed for 70-billion-parameter models, GPU scheduling, or autonomous AI agents. And yet — here we are. There’s a quiet revolution happening in the server rooms (and cloud accounts) of every serious tech organization right now. It doesn’t have […]
Kubernetes was built to run stateless web apps. Docker was built to ship software reliably. Neither was designed for 70-billion-parameter models, GPU scheduling, or autonomous AI agents. And yet — here we are.
There’s a quiet revolution happening in the server rooms (and cloud accounts) of every serious tech organization right now.
It doesn’t have a flashy product launch. Nobody’s putting it on a billboard. But if you’ve been watching the infrastructure space closely, you’ve felt it building for at least the last 18 months: Kubernetes and Docker are no longer just deployment tools — they’ve become the nervous system of modern AI.
That’s a big claim. Let’s back it up .
The Platform Convergence Nobody Planned For
When Kubernetes shipped its first stable release back in 2015, the pitch was simple: “stop babysitting servers, let the orchestrator handle it.”
The problems it solved were very real — scaling stateless microservices, rolling deployments, self-healing pods. Nobody was talking about GPU scheduling or petabyte-scale training pipelines.
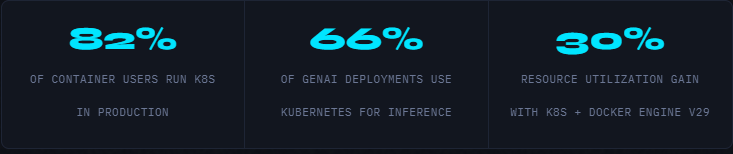
Fast forward to today. According to the CNCF annual survey released in January 2026, 82% of container users run Kubernetes in production, and a striking 66% of organizations hosting generative AI models use Kubernetes for some or all of their inference workloads.
The conversation has fundamentally shifted from stateless web applications to distributed training jobs, LLM inference, and autonomous AI agents.
Organizations that invest in reliable data management, flexible deployment strategies, and consistent recovery practices will be well-positioned as AI becomes central to enterprise growth.
The reason is almost embarrassingly practical. Running data processing, model training, inference serving, and agentic workflows on separate, disconnected infrastructure multiplies operational complexity at exactly the moment you need to move fast.
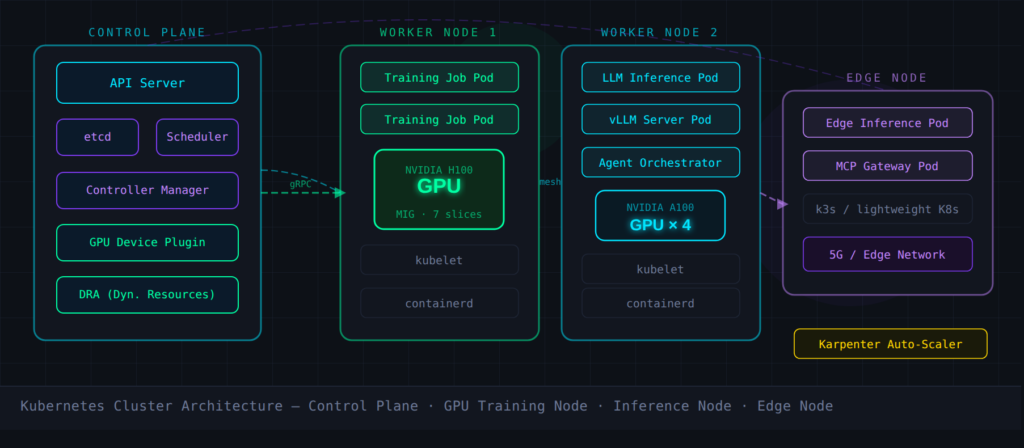
Kubernetes offers a unified control plane for all of them. That’s not a selling point. That’s a survival mechanism.
GPU Scheduling: The Hard Problem K8s Is Quietly Solving
Here’s where it gets technically interesting. The heaviest AI workloads on Kubernetes in 2026 are MLOps platforms — systems that demand the coordination of bursty, resource-intensive training jobs with high-volume, continuously running inference services.
These are fundamentally different workload types sitting on the same substrate, competing for expensive hardware.
Kubernetes is addressing this through a stack of primitives that didn’t exist two years ago:
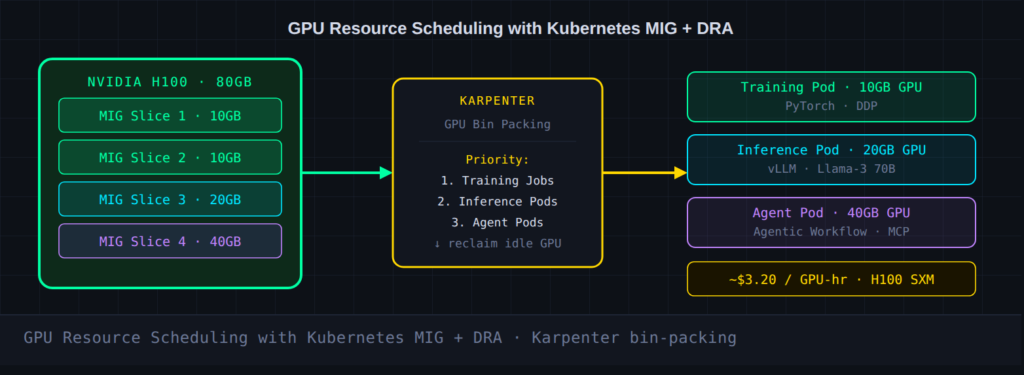
⚡ GPU Scheduling Toolkit in 2026
MIG (Multi-Instance GPU) — partitions a single GPU into isolated, right-sized slices.DRA (Dynamic Resource Allocation) — moves beyond static device plugins to allow runtime GPU partitioning and reassignment between pods.Karpenter — provisions the exact node types needed and aggressively deprovisions idle capacity, keeping GPU bills from spiraling.SOCI (Seekable OCI) — accelerates startup times for large model-serving containers, slashing the cold-start penalty that was killing autoscaling efficiency.
The goal is bin-packing GPU jobs intelligently, prioritizing critical training runs, and ensuring idle accelerator capacity gets reclaimed.
Given that a single H100 node can cost over $3 per GPU-hour, the financial argument for this level of orchestration precision is compelling even before you get to the engineering benefits.
Docker’s Second Act: From Shipping Containers to Shipping Agents
Meanwhile, Docker has been doing something unexpected: quietly reinventing itself as the local development companion for an AI-first world.
The launch of Docker Kanvas in early 2026 is the clearest signal of this shift — it converts docker-compose.yml files into Kubernetes manifests automatically, generates architecture visualizations, and positions Docker as the bridge between a developer’s laptop and a production cluster.
More interesting still is what’s happening with Docker Model Runner and its new vLLM backend for macOS.
As of February 2026, Docker supports vLLM 0.5.2 with Metal GPU acceleration on Apple Silicon. Benchmarks on an M2 Pro MacBook Pro showed a 35% reduction in inference latency and a 40% increase in throughput when running a 70B parameter model compared to previous versions. That’s not a toy benchmark. That’s local AI development becoming genuinely viable.
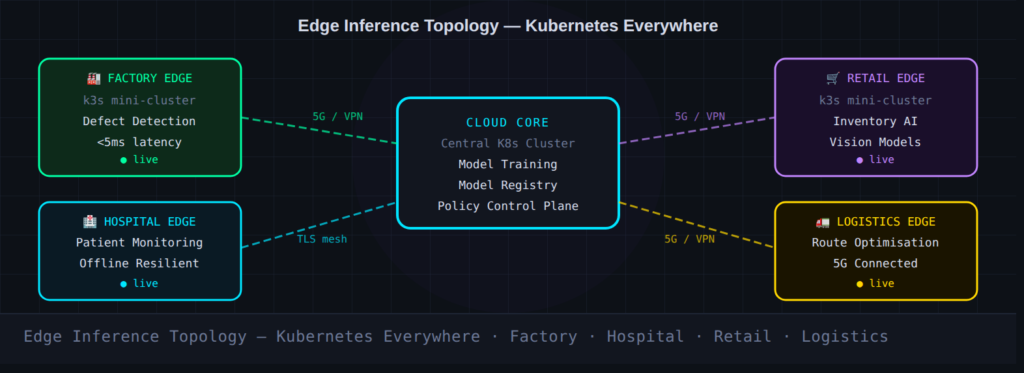
Edge Inference: The Trend That Snuck Up on Everyone
There’s a growing category of AI workloads that simply cannot tolerate the latency of central cloud processing. Real-time defect detection on a factory floor. Autonomous inventory tracking in retail. Predictive patient monitoring in a hospital with inconsistent connectivity.
The answer emerging across manufacturing, healthcare, logistics and retail is small Kubernetes clusters deployed directly where data is created — the so-called “edge cluster” pattern.
The proliferation of 5G and 6G connectivity is accelerating this trend dramatically. The digital workloads of the future will rely on speedy, local inferencing to deliver that instant, responsive experience users have come to expect.
Managing these distributed mini-clusters at scale is a genuine operational challenge, and it’s pushing teams toward multi-cluster scheduling solutions and centralized control planes that can govern hundreds of edge deployments from a single point of policy.
Agentic AI Is Rewriting the Security Rulebook
Perhaps the most disruptive shift in 2026 isn’t about performance — it’s about autonomy. Kubernetes environments are increasingly hosting agent-based workloads: AI systems that don’t just respond to requests, but reason, plan, and execute actions across services.
This creates security challenges that traditional network policies weren’t designed for. When a pod has a fixed function, you can write deterministic access rules for it.
When that pod is running an AI agent that decides at runtime which APIs to call, your threat model changes fundamentally. Platform teams in 2026 are scrambling to implement:
🔐 Security Primitives for Agentic K8s
- Workload identity — fine-grained identity for every agent, not just every service
- Policy-as-code — automated policy enforcement with dry-run workflows and full auditability
- Gateway API — replacing legacy Ingress controllers with expressive, extensible traffic rules
- Service mesh revival — simplified architectures (node-level proxies, ambient mode) making meshes practical again
The Docker MCP (Model Context Protocol) Gateway is tackling a related problem: it acts as a unified control plane, consolidating multiple MCP servers into a single endpoint, which streamlines coordination of AI agents across multi-cloud and hybrid environments.
For enterprises operating in complex infrastructure, this kind of governance layer isn’t optional — it’s existential.
What This Means If You’re Building in 2026
If you’re a platform engineer, an SRE, or a developer who ships infrastructure, the message from the community is consistent: the question isn’t whether Kubernetes wins — it already has. The real question is how deliberately you’re using it.
Teams that are pulling ahead are treating AI infrastructure as an integrated ecosystem rather than a collection of disconnected parts. They’re standardizing telemetry and event schemas so AI-assisted observability can actually work.
They’re using Internal Developer Platforms (IDPs) to offer reusable, secure building blocks that behave the same way in every environment — local dev, staging, cloud, edge.
And perhaps most importantly, they’re piloting deliberately. Pick a small but meaningful slice of your footprint, validate your 2026 practices there — platform-driven self-service, secure-by-default templates, cost targets with teeth — and then roll what works into the platform as the new default.
★ Key Takeaways
- Kubernetes is now the unified AI operating layer. 66% of GenAI inference workloads run on K8s in production as of early 2026 (CNCF survey).
- GPU scheduling is the critical capability gap. Tools like DRA, Karpenter, and MIG partitioning are essential for cost-efficient AI infrastructure.
- Docker has pivoted to bridge local dev and cloud production. Docker Kanvas, Model Runner with vLLM, and the MCP Gateway signal a deliberate repositioning.
- Edge inference is a real workload pattern, not a future trend. Manufacturing, healthcare, and retail are deploying mini-clusters at the edge today.
- Agentic AI demands a new security model. Workload identity, policy-as-code, and Gateway API adoption are becoming mandatory in AI-forward clusters.
Facing similar challenges?
Our team of architects can help you implement these patterns in your organization.
Schedule a Free Architecture ReviewRelated Articles
AWS vs Azure vs GCP: The Ultimate 2026 Startup Cost Comparison
For a tech startup in 2026, the cloud is no longer just “infrastructure.” It is the engine of your innovation. However, that engine can quickly consume your entire seed round if you don’t manage it properly. Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) have shifted their strategies this year. They are […]

How to Estimate Cloud Infrastructure Cost in 2026
You are about to build something in the cloud — or you are already running something, and the bill keeps surprising you. Either way, you need a number you can trust. This guide shows you exactly how to estimate cloud infrastructure costs, layer by layer, without guesswork. Cloud infrastructure cost breaks into four main layers […]